
通知设置 新通知
【GALA】广告活动本地化基本指南
本地化行业 • 张晓彤 发表了文章 • 0 个评论 • 445 次浏览 • 2019-05-02 22:00
概要:
这篇文章简述了广告活动本地化的基本流程,从市场营销的角度提供了一些工作思路和值得关注的细节。
作为市场营销的重要手段,广告活动可以对产品和服务进行宣传。符合社会价值和市场需求的广告可以有效提高品牌知名度,吸引客户。
在品牌国际化的过程中,企业应当根据不同市场的情况相应调整广告,而面对不同地区的语言和文化,需要采用不同特色的本地化策略。
本文将广告本地化分为以下六个步骤:
1. 前期准备
在本地化前期,先做好全局规划,进行市场调研,洞察受众与需求,判断源广告在目标市场是否适合,以确定定制化程度和策略,和所需人力及经费。
2. 关注文化
不同地区有不同的文化,“一刀切”的方法不可能适用于所有市场,一成不变的广告难以吸睛。根据目标地区的特点制定营销策略,从历史、风俗、甚至法律等方面分析文化差异,抓住其价值、兴趣及热点。
3. 确定基调
根据受众身份、年龄等特点,确定广告基调正式与否,并恰当用词。需要注意人称的转换,例如英文中没有“你”和“您”的差别,而目标语言中或许并非如此;同一种语言在不同的地区也存在用法差异,例如西班牙语人称在哥伦比亚的特殊用法。
4. 创译
广告本地化不仅仅是翻译,而是对内容的再创作。除了文案以外,企业名称、标语、宣传册等也需要由目标地区的相关专家进行改良,以符合当地实际,通过不同的方式传递相同的品牌信息。
5. 视觉处理
图像是广告中最直观的部分,第一印象十分重要。应当考虑颜色、图形和符号蕴含的文化含义,避免造成误解。
6. 营销渠道
定位合适的渠道进行宣传,可以在展示优质内容的基础上,提升曝光率。在网络发达的地区,可以通过当地流行的社交网站发布广告;在传统媒体占优势的地区,则可以利用电视、报纸、广播等开展宣传。还应根据目标地区使用的搜索引擎,有针对性地进行搜索引擎优化,例如谷歌在美国很常用,在亚洲则落后于雅虎,百度和Naver。
广告活动是产品和服务的门面,无论是初期的策划,还是后续的本地化,都需要从多个角度仔细考量。
思考:
1. 本地化
翻译是本地化的真子集,本地化过程中还需注意阅读习惯、接入平台等方面。成果最终是为人所用,因此本地化人员不仅要从自己的视角出发,更要站在最终用户的立场思考。万金油难寻,除了本文中建议的以当地货币进行报价,还有很多需要考虑的细节,例如计量单位、数字和日期格式、布局排版、甚至功能等。不恰当的本地化举措不仅不实用,还可能闹出笑话,例如目前引导中国观众到谷歌搜索,或到油管观看更多内容的广告肯定不妥;引导中国玩家使用脸书或推特登录的游戏也不合理,不支持支付宝或微信支付进行付费更是欠考虑。
2. 营销
4P营销组合策略,即产品Product、价格Price、渠道Place和推广Promotion相结合。在企业进入新市场的过程中,产品、价格和渠道和推广需要进行本地化,而推广及运营等关键部分恐怕很难由本地化公司代劳。因此建立本地化部门或招聘本地化人员是更好的选择,但还需平衡人力成本与营收利润。
问题:
本地化中还有哪些容易被忽略的小细节呢?
术语:
Advertising campaign / 广告活动
Media channel / 媒体渠道
Transcreate / 创译
Cultural nuance / 文化差异
作者:
张晓彤
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向) 查看全部
概要:
这篇文章简述了广告活动本地化的基本流程,从市场营销的角度提供了一些工作思路和值得关注的细节。
作为市场营销的重要手段,广告活动可以对产品和服务进行宣传。符合社会价值和市场需求的广告可以有效提高品牌知名度,吸引客户。
在品牌国际化的过程中,企业应当根据不同市场的情况相应调整广告,而面对不同地区的语言和文化,需要采用不同特色的本地化策略。
本文将广告本地化分为以下六个步骤:
1. 前期准备
在本地化前期,先做好全局规划,进行市场调研,洞察受众与需求,判断源广告在目标市场是否适合,以确定定制化程度和策略,和所需人力及经费。
2. 关注文化
不同地区有不同的文化,“一刀切”的方法不可能适用于所有市场,一成不变的广告难以吸睛。根据目标地区的特点制定营销策略,从历史、风俗、甚至法律等方面分析文化差异,抓住其价值、兴趣及热点。
3. 确定基调
根据受众身份、年龄等特点,确定广告基调正式与否,并恰当用词。需要注意人称的转换,例如英文中没有“你”和“您”的差别,而目标语言中或许并非如此;同一种语言在不同的地区也存在用法差异,例如西班牙语人称在哥伦比亚的特殊用法。
4. 创译
广告本地化不仅仅是翻译,而是对内容的再创作。除了文案以外,企业名称、标语、宣传册等也需要由目标地区的相关专家进行改良,以符合当地实际,通过不同的方式传递相同的品牌信息。
5. 视觉处理
图像是广告中最直观的部分,第一印象十分重要。应当考虑颜色、图形和符号蕴含的文化含义,避免造成误解。
6. 营销渠道
定位合适的渠道进行宣传,可以在展示优质内容的基础上,提升曝光率。在网络发达的地区,可以通过当地流行的社交网站发布广告;在传统媒体占优势的地区,则可以利用电视、报纸、广播等开展宣传。还应根据目标地区使用的搜索引擎,有针对性地进行搜索引擎优化,例如谷歌在美国很常用,在亚洲则落后于雅虎,百度和Naver。
广告活动是产品和服务的门面,无论是初期的策划,还是后续的本地化,都需要从多个角度仔细考量。
思考:
1. 本地化
翻译是本地化的真子集,本地化过程中还需注意阅读习惯、接入平台等方面。成果最终是为人所用,因此本地化人员不仅要从自己的视角出发,更要站在最终用户的立场思考。万金油难寻,除了本文中建议的以当地货币进行报价,还有很多需要考虑的细节,例如计量单位、数字和日期格式、布局排版、甚至功能等。不恰当的本地化举措不仅不实用,还可能闹出笑话,例如目前引导中国观众到谷歌搜索,或到油管观看更多内容的广告肯定不妥;引导中国玩家使用脸书或推特登录的游戏也不合理,不支持支付宝或微信支付进行付费更是欠考虑。
2. 营销
4P营销组合策略,即产品Product、价格Price、渠道Place和推广Promotion相结合。在企业进入新市场的过程中,产品、价格和渠道和推广需要进行本地化,而推广及运营等关键部分恐怕很难由本地化公司代劳。因此建立本地化部门或招聘本地化人员是更好的选择,但还需平衡人力成本与营收利润。
问题:
本地化中还有哪些容易被忽略的小细节呢?
术语:
Advertising campaign / 广告活动
Media channel / 媒体渠道
Transcreate / 创译
Cultural nuance / 文化差异
作者:
张晓彤
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向)
【TAUS】修复翻译生态系统
本地化行业 • 陈鑫 发表了文章 • 0 个评论 • 554 次浏览 • 2019-04-29 22:46
概要:
本文是TAUS网站的建立者Jaap van der Meer在2018年10月30日发布在其网站上的一篇文章。作者认为,由于机器翻译和人工智能等新技术的出现,传统翻译生态系统已经不能满足翻译行业的持续健康发展需求。只有对现有的翻译生态进行改革,号召所有从业者一起行动,才能扭转局势。作者从三个方面提出了建议,分别是:
1. 修复知识差距
作者认为,人们目前对于机器翻译的失误过于敏感,而对于人工翻译的失误却有相当高的忍受能力。但是,已经有许多数据证明机器翻译在许多方面已经超过了人工翻译。这显示出大部分利益相关者并没有引起足够的重视。他们有意或无意地忽视了技术突破带来的影响,而新技术也许会颠覆整个行业。所以,作者认为翻译从业人员需要主动学习、熟练掌握新技术。翻译人员要成为拥有多种技能的复合型人才,同时,行业也要加大对培训和人力资本的投资。
2.修正操作差距
由于当前传统运营模式、企业指标、定价系统和协议等还相对独立,统一的测量、翻译度量还没有形成。作者认为,业界需要在基本生产原则上保持一致。并且还提出了一个测量指标,即TAUS DQF指标,希望推广这个指标,作为组织内部基准测试乃至整个行业规范标准。
3.缩小数据差距
数据已经成为了新的“石油”,成为了所有人希望控制的对象。要消除差异,实际上要尽可能的缩小人们输入引擎的数据差异。作者认为需要改变传统收集数据的方法,而建立“数据市场”是最有效的方式。从业者可以生成数据,在市场中销售、交换数据,运用市场“看不见的手”来促使数据更新、引擎调整。“数据市场“将造福整个翻译行业的从业者。
这些建议都被写进了名为《Nunc Est Tempus》的电子书之中。作者呼吁整个翻译界,行业内的买家和卖家、运营商和从业者,政策制定者一道修复翻译生态系统。
思考:
1. 新技术改变传统翻译行业的趋势势不可挡,唯有拥抱技术,加强提升个人能力,才能在未来的翻译行业中争得一席之地。
2. 不仅是翻译人员,整个行业也应该携手共进,共同应对新的形势、新的挑战。
问题:
1. 除了在专门学校里系统地学习翻译技术,业余翻译人员怎么才能提升综合能力、系统学习新技术知识呢?MOOC平台是否能成为一个好的学习途径?
术语:
Translation Ecosystem / 翻译生态系统
white paper / 白皮书
data marketplace / 数据市场
作者:
陈鑫
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向)
查看全部
概要:
本文是TAUS网站的建立者Jaap van der Meer在2018年10月30日发布在其网站上的一篇文章。作者认为,由于机器翻译和人工智能等新技术的出现,传统翻译生态系统已经不能满足翻译行业的持续健康发展需求。只有对现有的翻译生态进行改革,号召所有从业者一起行动,才能扭转局势。作者从三个方面提出了建议,分别是:
1. 修复知识差距
作者认为,人们目前对于机器翻译的失误过于敏感,而对于人工翻译的失误却有相当高的忍受能力。但是,已经有许多数据证明机器翻译在许多方面已经超过了人工翻译。这显示出大部分利益相关者并没有引起足够的重视。他们有意或无意地忽视了技术突破带来的影响,而新技术也许会颠覆整个行业。所以,作者认为翻译从业人员需要主动学习、熟练掌握新技术。翻译人员要成为拥有多种技能的复合型人才,同时,行业也要加大对培训和人力资本的投资。
2.修正操作差距
由于当前传统运营模式、企业指标、定价系统和协议等还相对独立,统一的测量、翻译度量还没有形成。作者认为,业界需要在基本生产原则上保持一致。并且还提出了一个测量指标,即TAUS DQF指标,希望推广这个指标,作为组织内部基准测试乃至整个行业规范标准。
3.缩小数据差距
数据已经成为了新的“石油”,成为了所有人希望控制的对象。要消除差异,实际上要尽可能的缩小人们输入引擎的数据差异。作者认为需要改变传统收集数据的方法,而建立“数据市场”是最有效的方式。从业者可以生成数据,在市场中销售、交换数据,运用市场“看不见的手”来促使数据更新、引擎调整。“数据市场“将造福整个翻译行业的从业者。
这些建议都被写进了名为《Nunc Est Tempus》的电子书之中。作者呼吁整个翻译界,行业内的买家和卖家、运营商和从业者,政策制定者一道修复翻译生态系统。
思考:
1. 新技术改变传统翻译行业的趋势势不可挡,唯有拥抱技术,加强提升个人能力,才能在未来的翻译行业中争得一席之地。
2. 不仅是翻译人员,整个行业也应该携手共进,共同应对新的形势、新的挑战。
问题:
1. 除了在专门学校里系统地学习翻译技术,业余翻译人员怎么才能提升综合能力、系统学习新技术知识呢?MOOC平台是否能成为一个好的学习途径?
术语:
Translation Ecosystem / 翻译生态系统
white paper / 白皮书
data marketplace / 数据市场
作者:
陈鑫
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向)
【GALA】从印加时代到数字时代:新媒体、新故事和译者的角色——冉冉升起的新星
本地化行业 • sunrui 发表了文章 • 0 个评论 • 423 次浏览 • 2019-04-28 22:25
概要:
这篇文章通过2018年GALA新星奖学金竞赛获奖者之一劳拉·里纳雷斯的获奖论文,对新媒体对翻译任务与方法的影响等问题做出了回答。
文章主要包括以下几个部分:
1.介绍
计算机辅助翻译工具和自动化翻译等数字革命的产物,也就是新媒体,会对翻译和本地化行业产生不小的影响,对译者有利有弊,还会引起叙事方面的变化。
2.新媒体、新规则:技术在叙事建构和故事传播方面的影响
技术的进步引起了叙事方式的变化,印加人的传统结绳编码“quipu”近来被破译,这个编码的破译有助于人类理解语言的转变。为秘鲁土著人发声的交互式网站纪录片“古秘鲁结绳文字项目”正是使用了新媒体,它体现了新媒体的两大特点:参与性与互动性。
3.轮回:马琳切,一个混合的世界和译者在社会中的新角色
古代著名的翻译马琳切使人们始终对译者保有背叛者的印象,认为作者地位高于译者,但在现代翻译和新媒体结合后这个想法不会再成立了。“古秘鲁结绳文字项目”就是多元化协作和多语种交流的成功例子。译者借助技术可以在原文的基础上创造新的故事,将在语言文化全球化的过程中发挥突出作用。
思考:
1.将新媒体(视频本地化,电子教学等)与翻译结合好
作为助力文化全球化的新起之秀,新媒体应该成为译者掌握的一种技能,或是应用于文化翻译传播过程中的工具。
2.技术和语言的变化是息息相关的
语言和技术的进步也促成了人们叙事方式的变化。
问题:
怎样将新媒体广泛应用于翻译中?
术语:
metizo 混血的
quipu 古秘鲁人的结绳文字
indigenous Peruvians 秘鲁土著人
Quechua 盖丘亚语
the Nouveau Roman movement 新小说运动
作者:
孙睿
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向)
查看全部
概要:
这篇文章通过2018年GALA新星奖学金竞赛获奖者之一劳拉·里纳雷斯的获奖论文,对新媒体对翻译任务与方法的影响等问题做出了回答。
文章主要包括以下几个部分:
1.介绍
计算机辅助翻译工具和自动化翻译等数字革命的产物,也就是新媒体,会对翻译和本地化行业产生不小的影响,对译者有利有弊,还会引起叙事方面的变化。
2.新媒体、新规则:技术在叙事建构和故事传播方面的影响
技术的进步引起了叙事方式的变化,印加人的传统结绳编码“quipu”近来被破译,这个编码的破译有助于人类理解语言的转变。为秘鲁土著人发声的交互式网站纪录片“古秘鲁结绳文字项目”正是使用了新媒体,它体现了新媒体的两大特点:参与性与互动性。
3.轮回:马琳切,一个混合的世界和译者在社会中的新角色
古代著名的翻译马琳切使人们始终对译者保有背叛者的印象,认为作者地位高于译者,但在现代翻译和新媒体结合后这个想法不会再成立了。“古秘鲁结绳文字项目”就是多元化协作和多语种交流的成功例子。译者借助技术可以在原文的基础上创造新的故事,将在语言文化全球化的过程中发挥突出作用。
思考:
1.将新媒体(视频本地化,电子教学等)与翻译结合好
作为助力文化全球化的新起之秀,新媒体应该成为译者掌握的一种技能,或是应用于文化翻译传播过程中的工具。
2.技术和语言的变化是息息相关的
语言和技术的进步也促成了人们叙事方式的变化。
问题:
怎样将新媒体广泛应用于翻译中?
术语:
metizo 混血的
quipu 古秘鲁人的结绳文字
indigenous Peruvians 秘鲁土著人
Quechua 盖丘亚语
the Nouveau Roman movement 新小说运动
作者:
孙睿
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向)
【slator】语言如何影响印度人上网行为
本地化行业 • SherryZhang 发表了文章 • 0 个评论 • 633 次浏览 • 2019-04-28 17:54
概要:
文章开头首先抛出一个现状:2019年,印度消费者使用的大多数产品和服务线下用印度语进行营销,线上则以英语支持。也就是说,传统渠道(如印刷和电视)的广告和营销早已转向印度语。
第二段写印度语言分布情况: 印度官方认可语言有22种之多,但一半以上人口讲印度语,可见印度语的重要性。
第三、四段讲印度公司尚未意识到印度语在线上起到的积极作用。以印度最大零售电商平台BigBasket为例,在其APP 或网站上,消费者很难见到印语。
第五段:印度语在线服务获暴利。印度语用户数量已达在互联2.34亿,增长速度超过英语用户。在印度排名前10的应用程序中,至少有7个提供本地语言支持,这不是巧合。这些应用程序并非源自印度,但开发商懂得本地化的重要性。
第二部分:购买决策。
前三段举例论证线上交易方式越来越流行。如果一位消费者决定换新手机,或者买辆车,她会先看看有没有最便宜、最符合她实际需求的产品。通常情况下,她会和一位最近可能购买过类似商品的朋友交谈,因为一手信息对她很重要。此外,她还通过网上阅读用户评论获得信息。
第四段通过对比两组数据说明线上用户猛增,线下渠道不再是影响印度消费者的主要因素。2014年尼尔森调查显示48%的消费者在购车之前会从网上搜集信息,而到了2018年这一比例达到89%。
第五段,用户生成内容平台Momspresso以及社交媒体网络ShareChat正在为地区语言用户提供一个用当地语言在线讨论、分享和互动的空间。然而,印度语内容广度仍然不如英语。
第三部分:让消费者付费。
网上付费有诸多渠道可选,许多人认为付费市场已经饱和,这是错误的认知。然而确实大部分印度消费者拒绝在网上付费。原因在于付费过程全以英文显示,消费者安全感何来?
第四部分:语音驱动。
2018年,三分之一的谷歌搜索是由语音驱动的。同年,沃尔玛支持的电子商务公司Flipkart收购了一家印度语音语言技术初创公司。印度领先的电信和互联网服务提供商Reliance Jio也对Reverie进行了类似收购。亚马逊Alexa也决定学习印度语言。
印度消费者与其他多语言社会的消费者没什么不同,他们喜欢你用他们的语言和他们交谈。印度的本地化曲线可能不完全像《voice》杂志一开始所显示的那样,与更成熟的经济体相似。但“本地化对印度来说可有可无”这一想法很危险。
思考:如何对一个项目进行本地化程度把控?一个会说中文的外国人比只会说本国语言的外国人更受欢迎,但是一个整成中国人相貌的外国人呢?
问题:印度市场如此广阔,为何本地化程度缓慢,是什么阻碍了本地化进程?
术语:
Nielsen 尼尔森
作者:张雪薇
北京语言大学高翻学院
2019级翻译专业硕士(本地化管理方向) 查看全部
概要:
文章开头首先抛出一个现状:2019年,印度消费者使用的大多数产品和服务线下用印度语进行营销,线上则以英语支持。也就是说,传统渠道(如印刷和电视)的广告和营销早已转向印度语。
第二段写印度语言分布情况: 印度官方认可语言有22种之多,但一半以上人口讲印度语,可见印度语的重要性。
第三、四段讲印度公司尚未意识到印度语在线上起到的积极作用。以印度最大零售电商平台BigBasket为例,在其APP 或网站上,消费者很难见到印语。
第五段:印度语在线服务获暴利。印度语用户数量已达在互联2.34亿,增长速度超过英语用户。在印度排名前10的应用程序中,至少有7个提供本地语言支持,这不是巧合。这些应用程序并非源自印度,但开发商懂得本地化的重要性。
第二部分:购买决策。
前三段举例论证线上交易方式越来越流行。如果一位消费者决定换新手机,或者买辆车,她会先看看有没有最便宜、最符合她实际需求的产品。通常情况下,她会和一位最近可能购买过类似商品的朋友交谈,因为一手信息对她很重要。此外,她还通过网上阅读用户评论获得信息。
第四段通过对比两组数据说明线上用户猛增,线下渠道不再是影响印度消费者的主要因素。2014年尼尔森调查显示48%的消费者在购车之前会从网上搜集信息,而到了2018年这一比例达到89%。
第五段,用户生成内容平台Momspresso以及社交媒体网络ShareChat正在为地区语言用户提供一个用当地语言在线讨论、分享和互动的空间。然而,印度语内容广度仍然不如英语。
第三部分:让消费者付费。
网上付费有诸多渠道可选,许多人认为付费市场已经饱和,这是错误的认知。然而确实大部分印度消费者拒绝在网上付费。原因在于付费过程全以英文显示,消费者安全感何来?
第四部分:语音驱动。
2018年,三分之一的谷歌搜索是由语音驱动的。同年,沃尔玛支持的电子商务公司Flipkart收购了一家印度语音语言技术初创公司。印度领先的电信和互联网服务提供商Reliance Jio也对Reverie进行了类似收购。亚马逊Alexa也决定学习印度语言。
印度消费者与其他多语言社会的消费者没什么不同,他们喜欢你用他们的语言和他们交谈。印度的本地化曲线可能不完全像《voice》杂志一开始所显示的那样,与更成熟的经济体相似。但“本地化对印度来说可有可无”这一想法很危险。
思考:如何对一个项目进行本地化程度把控?一个会说中文的外国人比只会说本国语言的外国人更受欢迎,但是一个整成中国人相貌的外国人呢?
问题:印度市场如此广阔,为何本地化程度缓慢,是什么阻碍了本地化进程?
术语:
Nielsen 尼尔森
作者:张雪薇
北京语言大学高翻学院
2019级翻译专业硕士(本地化管理方向)
Trados 分析报告中文件重复与交叉文件重复问题
SDL Trados Studio 2015 • Aemaeth_T 发表了文章 • 0 个评论 • 1296 次浏览 • 2019-04-28 14:32
韩林涛老师在其《CAT计算机辅助翻译入门》系列课程“第18讲如何理解报告视图中的‘重复’和‘交叉文件重复’”中提到Trados里导入单个或多个文件时如何理解分析报告中“重复”和“交叉文件重复”,同时给出了两个文件计算重复的案例并留下三个文件计算重复的“课后作业”。而我的同学D在回顾计算重复这一功能时发现了一些问题,以下为问题详情以及测试过程和结果。
二、过程及问题
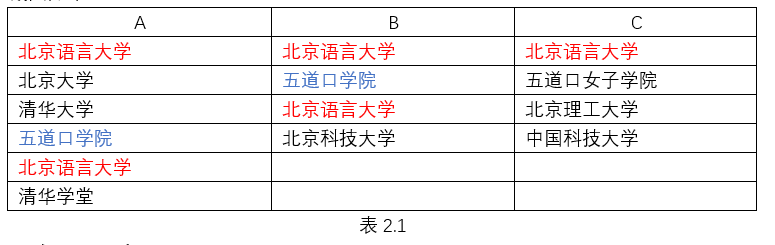
以下表格A、B、C分别代表A、B、C三个文档,韩林涛老师在视频中用这三个文档演示了“重复”和“交叉文件重复”的分析结果。我们在课后进行操作时分别导入A、AB、ABC来进行对比,为方便阅读,仅保留“重复”和“交叉文件重复”的结果:
1、仅导入A分析:
句段/字数
重复 1/6
交叉 0/0
2、导入AB分析:
重复 1/6
交叉 3/17
3、导入ABC分析:
重复 1/6
交叉 4/23
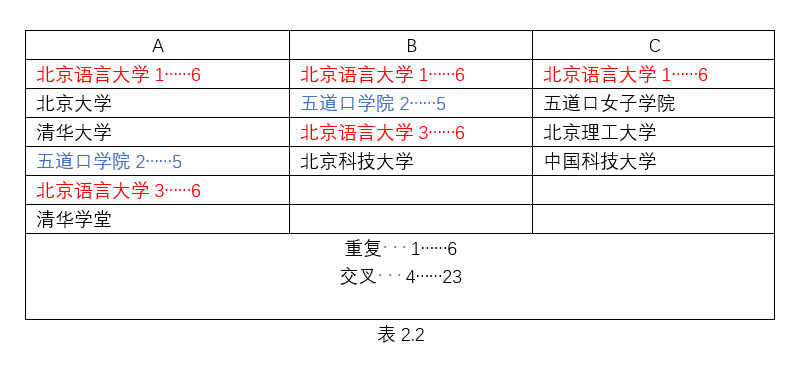
以上是三种情况的交叉重复分析的结果。下表(表2.2)为对照分析样本,表格中如“1……6”代表“句段……字数”,文字表示则为“1/6”,后同。
其中AB的交叉重复看上去似乎很好理解:按顺序一一对应即可,即AB交叉重复结果为A1B1+A2B2+A3B3=17,由此似乎可以推出文本内的重复句段——如A1A3和B1B3在计算交叉重复时会分别各算作一次重复,但是具体的运算过程是否真是如此?如果按照这种计算方法,再加入C之后交叉重复的结果便难以理解:
如果AC和BC间的重复各算作1次,结果应为A1B1+A2B2+A3B3+A1(A3)C1+B1(B3)C1=29,而非trados算出的4/23如果C与AB交叉重复的结果进行重复统计,即结果为A1B1+A2B2+A3B3+A1(B1)C1+A3(B3)C1=29
如果按照最初推测的两种方式去计算ABC的交叉重复,则无论C与A、B分别计算重复还是C与AB的重复结果再进行重复计算得出的结果都不吻合4/23。
三、测试及结论
测试
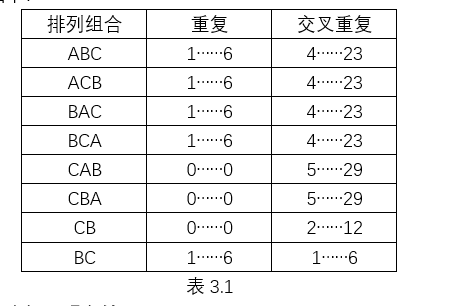
为了弄清实际的交叉重复计算方式,我分别调换A、B、C(名称不变)的文本内容并导入进行分析,结果如下:
由此可以得出几个初步观察的结果:
同样的n个文件如果排列顺序不同,重复和交叉重复结果会出现不同的情况。具体到这个案例,当C为第一个分析文件时(此时名称依然是A),文件内部重复为0/0,而交叉重复则变为5/29,可以据此推测第一个文件的内部重复对所在文件群的交叉重复会产生影响。若只导入CB得到交叉重复2/12的结果,BC则是1/6,显然这里的运算过程是前一个文件进行内部去重后、后一个文件对前一个文件进行扫描匹配重复句段。由此得出两个文件的情况下的运算过程。
若三个及以上文件呢?我们再来对比一下ABC和CBA的结果差异:
A内部重复句段合并为A0,则AB交叉重复为:B1A0+B2A2+B3A0=17。接着AB进行合并去重即此时AB中仅有1个“北京语言大学”的句段和1个“五道口学院”句段,此时再由C对AB进行匹配,得到1个重复句段。所以ABC交叉重复为B1A0+B2A2+B3A0+C1AB1=23。A(C)内部无重复句段,则A(C) B交叉重复为:B1A1+B3A1=12。接着A(C) B进行1)的步骤,A(C)BC(A)一共交叉重复为 B1A1+B3A1+C(A)1A(C)1+C(A)2A(C)2+C(A)3A(C)1=29。
2. 结论
分析报告中的“重复”和“交叉文件重复”分别指文件内的重复和文件间的重复。N个文件的交叉重复运算过程是每个文件在前面所有文件合并且去重的基础上计算重复,最终得到的“交叉文件重复”结果是所有这些迭代运算的总和。
3. 验证
根据结论推算,结果应为:
B1A0+B2A2+B3A0+C1AB1+C2AB6+C3AB5+C4AB4=6+5+6+6+6+6+4=39
重复 1 6
交叉 7 39
实测运行结果一致。
以上即为Trados 分析报告中文件重复与交叉文件重复问题的一个小测试,感谢您抽空阅读,文章中若有错误或不当之处欢迎批评指正。 查看全部
韩林涛老师在其《CAT计算机辅助翻译入门》系列课程“第18讲如何理解报告视图中的‘重复’和‘交叉文件重复’”中提到Trados里导入单个或多个文件时如何理解分析报告中“重复”和“交叉文件重复”,同时给出了两个文件计算重复的案例并留下三个文件计算重复的“课后作业”。而我的同学D在回顾计算重复这一功能时发现了一些问题,以下为问题详情以及测试过程和结果。
二、过程及问题
以下表格A、B、C分别代表A、B、C三个文档,韩林涛老师在视频中用这三个文档演示了“重复”和“交叉文件重复”的分析结果。我们在课后进行操作时分别导入A、AB、ABC来进行对比,为方便阅读,仅保留“重复”和“交叉文件重复”的结果:
1、仅导入A分析:
句段/字数
重复 1/6
交叉 0/0
2、导入AB分析:
重复 1/6
交叉 3/17
3、导入ABC分析:
重复 1/6
交叉 4/23
以上是三种情况的交叉重复分析的结果。下表(表2.2)为对照分析样本,表格中如“1……6”代表“句段……字数”,文字表示则为“1/6”,后同。
其中AB的交叉重复看上去似乎很好理解:按顺序一一对应即可,即AB交叉重复结果为A1B1+A2B2+A3B3=17,由此似乎可以推出文本内的重复句段——如A1A3和B1B3在计算交叉重复时会分别各算作一次重复,但是具体的运算过程是否真是如此?如果按照这种计算方法,再加入C之后交叉重复的结果便难以理解:
- 如果AC和BC间的重复各算作1次,结果应为A1B1+A2B2+A3B3+A1(A3)C1+B1(B3)C1=29,而非trados算出的4/23
- 如果C与AB交叉重复的结果进行重复统计,即结果为A1B1+A2B2+A3B3+A1(B1)C1+A3(B3)C1=29
如果按照最初推测的两种方式去计算ABC的交叉重复,则无论C与A、B分别计算重复还是C与AB的重复结果再进行重复计算得出的结果都不吻合4/23。
三、测试及结论
- 测试
为了弄清实际的交叉重复计算方式,我分别调换A、B、C(名称不变)的文本内容并导入进行分析,结果如下:
由此可以得出几个初步观察的结果:
- 同样的n个文件如果排列顺序不同,重复和交叉重复结果会出现不同的情况。
- 具体到这个案例,当C为第一个分析文件时(此时名称依然是A),文件内部重复为0/0,而交叉重复则变为5/29,可以据此推测第一个文件的内部重复对所在文件群的交叉重复会产生影响。
- 若只导入CB得到交叉重复2/12的结果,BC则是1/6,显然这里的运算过程是前一个文件进行内部去重后、后一个文件对前一个文件进行扫描匹配重复句段。由此得出两个文件的情况下的运算过程。
若三个及以上文件呢?我们再来对比一下ABC和CBA的结果差异:
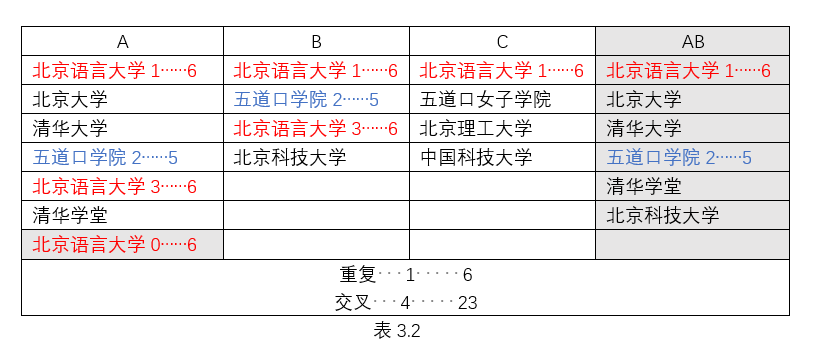
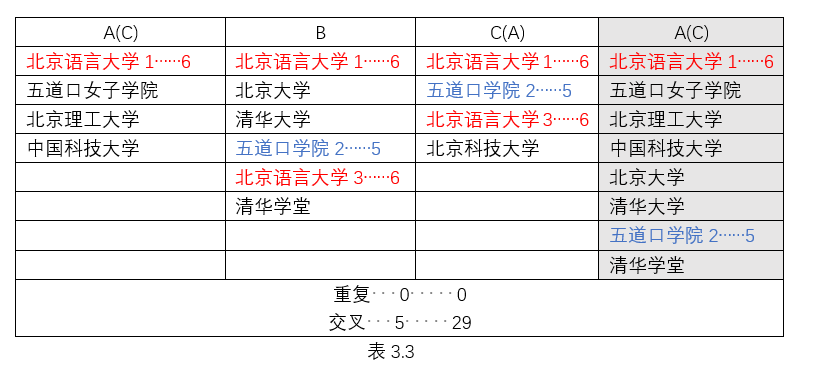
- A内部重复句段合并为A0,则AB交叉重复为:B1A0+B2A2+B3A0=17。接着AB进行合并去重即此时AB中仅有1个“北京语言大学”的句段和1个“五道口学院”句段,此时再由C对AB进行匹配,得到1个重复句段。所以ABC交叉重复为B1A0+B2A2+B3A0+C1AB1=23。
- A(C)内部无重复句段,则A(C) B交叉重复为:B1A1+B3A1=12。接着A(C) B进行1)的步骤,A(C)BC(A)一共交叉重复为 B1A1+B3A1+C(A)1A(C)1+C(A)2A(C)2+C(A)3A(C)1=29。
2. 结论
分析报告中的“重复”和“交叉文件重复”分别指文件内的重复和文件间的重复。N个文件的交叉重复运算过程是每个文件在前面所有文件合并且去重的基础上计算重复,最终得到的“交叉文件重复”结果是所有这些迭代运算的总和。
3. 验证
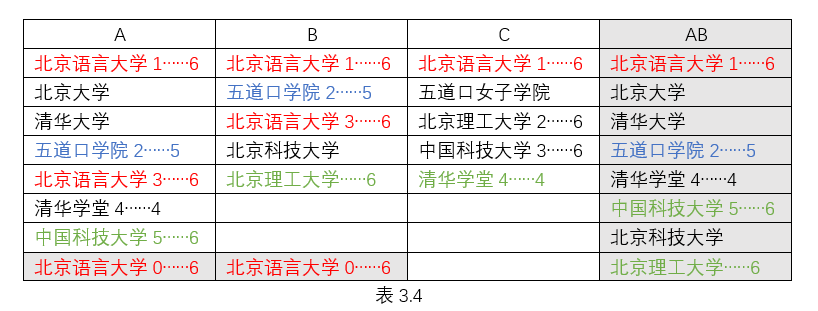
根据结论推算,结果应为:
B1A0+B2A2+B3A0+C1AB1+C2AB6+C3AB5+C4AB4=6+5+6+6+6+6+4=39
重复 1 6
交叉 7 39
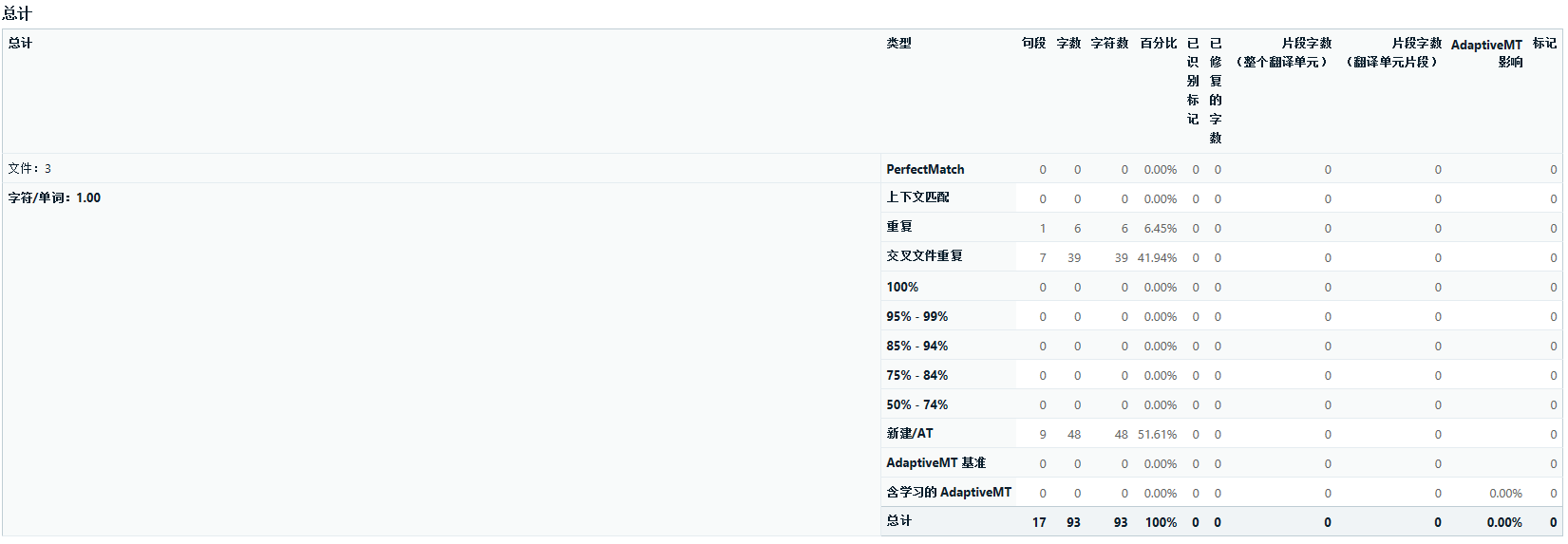
实测运行结果一致。
以上即为Trados 分析报告中文件重复与交叉文件重复问题的一个小测试,感谢您抽空阅读,文章中若有错误或不当之处欢迎批评指正。
如何在中英文混杂的文档中的给中英文之间添加/删除空格?
效率工具 • wnking7777 回复了问题 • 2 人关注 • 2 个回复 • 813 次浏览 • 2019-04-27 22:22
如何高效批量统计Word内中文字数?
效率工具 • wnking7777 回复了问题 • 1 人关注 • 1 个回复 • 978 次浏览 • 2019-04-25 16:36
【SLATOR】亚洲语言神经网络机器翻译现状
本地化行业 • 张晓彤 发表了文章 • 1 个评论 • 947 次浏览 • 2019-04-25 16:02
概要:
这篇文章概括了亚洲语言资源现状及其对神经网络机器翻译的影响,提出了现有的应对方案和未来的努力方向。
近年来,亚洲经济发展,各国交流需求增多,神经网络机器翻译是大势所趋,一些企业也开始为此项研究贡献力量。由于当下许多亚洲语言资源不充足,且载体非罗马文字,所以研究难度仍然较大。
Slator以访谈的形式邀请两位专家回答亚洲语言神经网络机器翻译相关问题,他们分别是:
刘伍颖先生,现就职于广东外语外贸大学的语言工程与计算实验室,发表学术论文并管理机器翻译与语言资源论坛。
Lucy Park女士,现就职于韩国搜索引擎巨头公司Naver,旗下的翻译软件拥有千万用户。
采访内容主要涵盖以下三个方面:
一、 亚洲低资源语言现状及应对方案
刘伍颖准备研发机器翻译系统,将东盟国家的语言转换为中文,让自然语言处理更好地为贸易文化交流服务。他研究的一个重点是将自然语言处理技术与适当人工干预相结合,建立双语语料库。随着技术不断进步,代码不是问题,大规模语料库才是瓶颈。
东南亚语言资源十分稀缺,在没有优质双语语料库的情况下,刘伍颖主张使用源语言中意义或主题相近的文本对,建立对比语料库。同源语言之间的转移学习可以有效缓解资源上的限制,生成式对抗网络等深度学习模型也可以降低机器学习对数据的依赖。
Lucy Park认为由于亚洲语言结构复杂,所以拆分语素和标注词性十分重要。同时还要考虑到不同语言的特点,例如韩语中有敬语平语之分,还经常省略主语。
二、 东西方自然语言处理和神经网络机器翻译
刘伍颖提出西方语言多为同源,且采用拉丁文字,欧盟组织也为各种语言交流提供了良好环境;亚洲语言来源复杂多样,且语料库不足,自然语言处理和神经网络机器翻译正处于资源积累阶段,但势头良好,前景开阔。
Lucy Park提出现有的大多数机器翻译方法都以英-德、英-法等西方主要语言对为基准,不一定适用于亚洲语言。针对亚洲语言独特的语法和书写系统,立足语言特点进行合理改良,可以促进亚洲自然语言处理和神经网络机器翻译的研究。因此开放源代码和数据的意义重大,她本人也致力于开发韩语分词标注组件KoNLPy。
三、 亚洲语言神经网络机器翻译的未来
去年以来,人们的关注范围愈加广泛,除中日韩语言之外,关于东南亚语言翻译的研究也越来越多,坚持纵向研究,兼顾横向发展。
亚洲许多学术机构和互联网企业活跃在亚洲语言神经网络机器翻译领域,人工智能和开源项目加速了更适应亚洲市场的产品和服务出现。
思考:
1. 亚洲语言之间的转换
在Naver搜索关于Lucy Park的信息时,使用谷歌翻译进行韩译中的效果确实不佳,译文不是很通顺,一些短词的译文甚至不达意;但将英语作为桥梁,先进行韩译英,再英译中,效果就会好一些。使用Naver开发的翻译工具Papago直接进行韩译中,译文相比之下优于谷歌翻译的产物。以上测试虽然不够全面,但面对亚洲语言之间的转换,应当多考虑语言特色,有针对性的处理。
2. 分词标注
在语言学习和机器翻译中,词性扮演着着烟雾弹般令人又爱又恨的重要角色。“一把把把手把住”这短短的一句话里就出现了“把”字的三种词性。不同的断句方法能够赋予同一句话不同的含义,“下雨天留客天留我不留”,美感与歧义同在。在训练机器去理解语义的过程中,拆分词句和标注词性起到了十分重要的作用,恰当的处理可以有效提高译文准确率。
3. 语料库
在自然语言处理中,使用和建立标准且丰富的语料库意义重大。机器翻译的本质与语音识别和音字转换的本质一样,都是转换问题。语音识别是将音频转换成文字,所以标准的语音输入是关键。然而许多语音语料在录制时就存在错读、错断和语气不当的现象,影响了语音识别的准确度。关于音字转换,目前网络上含有中文拼音与文字一一对应的完整读物的语料库寥寥无几。大多数在线拼音标注类网站提供的结果已经是算法生成的产物,不能作为严谨的实验数据使用。哈尔滨工业大学自然语言处理实验室的WI输入法使用的语料是人民日报1997年至2007年的所有文章,其拼音由机器自动标注与人工添加逻辑相结合生成。虽然严谨的语料带来的效果很好,但也暴露了一些问题,比如逻辑没有覆盖的拼音标注数据成为了实验噪声,语料缺乏时效性且具有内容局限性,毕竟流行用语和新兴词汇在人民日报中鲜有出现,而这些词的读音往往比普通词汇更加特别。由以上两个例子可以得见,在建立语料库时不仅需要标准,还要保证丰富度。
问题:
在激烈的商业竞争背景下,如何推动源代码和数据的开放?
术语:
Neutral Machine Translation (NMT) / 神经网络机器翻译
Natural Language Processing (NLP) / 自然语言处理
Language-centric AI / 以语言为中心的人工智能
Low-resource language / 低资源语言
SEA language / 东南亚语言
Generative Adversarial Network (GAN) / 生成式对抗网络
General Public License (GPL) / 通用公共授权协议
作者:
张晓彤
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向) 查看全部
概要:
这篇文章概括了亚洲语言资源现状及其对神经网络机器翻译的影响,提出了现有的应对方案和未来的努力方向。
近年来,亚洲经济发展,各国交流需求增多,神经网络机器翻译是大势所趋,一些企业也开始为此项研究贡献力量。由于当下许多亚洲语言资源不充足,且载体非罗马文字,所以研究难度仍然较大。
Slator以访谈的形式邀请两位专家回答亚洲语言神经网络机器翻译相关问题,他们分别是:
刘伍颖先生,现就职于广东外语外贸大学的语言工程与计算实验室,发表学术论文并管理机器翻译与语言资源论坛。
Lucy Park女士,现就职于韩国搜索引擎巨头公司Naver,旗下的翻译软件拥有千万用户。
采访内容主要涵盖以下三个方面:
一、 亚洲低资源语言现状及应对方案
刘伍颖准备研发机器翻译系统,将东盟国家的语言转换为中文,让自然语言处理更好地为贸易文化交流服务。他研究的一个重点是将自然语言处理技术与适当人工干预相结合,建立双语语料库。随着技术不断进步,代码不是问题,大规模语料库才是瓶颈。
东南亚语言资源十分稀缺,在没有优质双语语料库的情况下,刘伍颖主张使用源语言中意义或主题相近的文本对,建立对比语料库。同源语言之间的转移学习可以有效缓解资源上的限制,生成式对抗网络等深度学习模型也可以降低机器学习对数据的依赖。
Lucy Park认为由于亚洲语言结构复杂,所以拆分语素和标注词性十分重要。同时还要考虑到不同语言的特点,例如韩语中有敬语平语之分,还经常省略主语。
二、 东西方自然语言处理和神经网络机器翻译
刘伍颖提出西方语言多为同源,且采用拉丁文字,欧盟组织也为各种语言交流提供了良好环境;亚洲语言来源复杂多样,且语料库不足,自然语言处理和神经网络机器翻译正处于资源积累阶段,但势头良好,前景开阔。
Lucy Park提出现有的大多数机器翻译方法都以英-德、英-法等西方主要语言对为基准,不一定适用于亚洲语言。针对亚洲语言独特的语法和书写系统,立足语言特点进行合理改良,可以促进亚洲自然语言处理和神经网络机器翻译的研究。因此开放源代码和数据的意义重大,她本人也致力于开发韩语分词标注组件KoNLPy。
三、 亚洲语言神经网络机器翻译的未来
去年以来,人们的关注范围愈加广泛,除中日韩语言之外,关于东南亚语言翻译的研究也越来越多,坚持纵向研究,兼顾横向发展。
亚洲许多学术机构和互联网企业活跃在亚洲语言神经网络机器翻译领域,人工智能和开源项目加速了更适应亚洲市场的产品和服务出现。
思考:
1. 亚洲语言之间的转换
在Naver搜索关于Lucy Park的信息时,使用谷歌翻译进行韩译中的效果确实不佳,译文不是很通顺,一些短词的译文甚至不达意;但将英语作为桥梁,先进行韩译英,再英译中,效果就会好一些。使用Naver开发的翻译工具Papago直接进行韩译中,译文相比之下优于谷歌翻译的产物。以上测试虽然不够全面,但面对亚洲语言之间的转换,应当多考虑语言特色,有针对性的处理。
2. 分词标注
在语言学习和机器翻译中,词性扮演着着烟雾弹般令人又爱又恨的重要角色。“一把把把手把住”这短短的一句话里就出现了“把”字的三种词性。不同的断句方法能够赋予同一句话不同的含义,“下雨天留客天留我不留”,美感与歧义同在。在训练机器去理解语义的过程中,拆分词句和标注词性起到了十分重要的作用,恰当的处理可以有效提高译文准确率。
3. 语料库
在自然语言处理中,使用和建立标准且丰富的语料库意义重大。机器翻译的本质与语音识别和音字转换的本质一样,都是转换问题。语音识别是将音频转换成文字,所以标准的语音输入是关键。然而许多语音语料在录制时就存在错读、错断和语气不当的现象,影响了语音识别的准确度。关于音字转换,目前网络上含有中文拼音与文字一一对应的完整读物的语料库寥寥无几。大多数在线拼音标注类网站提供的结果已经是算法生成的产物,不能作为严谨的实验数据使用。哈尔滨工业大学自然语言处理实验室的WI输入法使用的语料是人民日报1997年至2007年的所有文章,其拼音由机器自动标注与人工添加逻辑相结合生成。虽然严谨的语料带来的效果很好,但也暴露了一些问题,比如逻辑没有覆盖的拼音标注数据成为了实验噪声,语料缺乏时效性且具有内容局限性,毕竟流行用语和新兴词汇在人民日报中鲜有出现,而这些词的读音往往比普通词汇更加特别。由以上两个例子可以得见,在建立语料库时不仅需要标准,还要保证丰富度。
问题:
在激烈的商业竞争背景下,如何推动源代码和数据的开放?
术语:
Neutral Machine Translation (NMT) / 神经网络机器翻译
Natural Language Processing (NLP) / 自然语言处理
Language-centric AI / 以语言为中心的人工智能
Low-resource language / 低资源语言
SEA language / 东南亚语言
Generative Adversarial Network (GAN) / 生成式对抗网络
General Public License (GPL) / 通用公共授权协议
作者:
张晓彤
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向)
【Slator】面向亚洲语言的神经机器翻译发展现状
行业动态 • Yur1Van 发表了文章 • 0 个评论 • 528 次浏览 • 2019-04-25 10:36
概要:
由于亚洲国家的语言都缺乏大规模、高质量、广覆盖率的平行语料库,对于语言服务提供者而言,去拓展这样一个市场会产生重大经济、文化和技术的效应,因此,近年发展迅速的神经机器翻译面临不少挑战和机遇,Slator编辑Gino Diño就面向亚洲语言的神经机器翻译发展的相关问题采访了两位专家,分别是在2018亚洲语言自然语言处理国际会议发布论文的刘伍颍研究员和Naver公司的机器翻译研究科学家露西·帕克(Lucy Park)。
亚洲语言的神经机器翻译发展面临的挑战:缺乏可用的语料。
刘伍颖博士称,低资源语言的机器翻译训练数据来源:高校语言专业的教师和学生,建立可比语料库,迁移学习同族语言,以及运用近期热门的生成对抗网络GAN(Generative Adversarial Network)和无监督学习。
亚洲语言的自然语言处理以及神经机器翻译发展态势:未来可期,相较于西方国家语言的发展而言,亚洲语言研究尚处于资源积累的阶段。露西认为,主要基于英德、英法语言对之上的研究,对亚洲语言的研究的有效性有待考证。
如何激发面向亚洲语言的神经机器翻译研究活力:露西认为首先要发展语言专业知识;其次是有公开可用、无版权限制的研究数据;最后,需要更多自然语言处理的开源项目。
面向亚洲语言的NLP和NMT发展中最有潜力的领域:刘伍颖博士认为贸易、电子商务以及技术方面的翻译将获得重点关注。露西•帕克则认为非拉丁文字的自然语言处理以及克服文化语言困难将成为发展潜力巨大的领域。
最后,两位专家还提到目前该领域研究发展较好的学术机构和国内外公司,以及值得关注的技术。
思考:
(1)亚洲语言的语料不足,体现了此前这些国家翻译文化事业发展落后,不少是由于这些国家经济、文化实力不强等历史原因造成的。翻译事业的发展,意味着国家的开放、技术的引进、思想的碰撞、社会的进步。随着 “一带一路”丝绸之路经济带的深入发展,小语种国家将成为经贸、文化、技术开发的新市场,语言服务需求随之也将呈现指数增长。因此,面向这些小语种国家语言的机器翻译发展前景巨大,但想要克服语料资源不足的限制,需要相关学科加大科研力度,仍有很长的路要走。
(2)全世界有7000多种语言,平均每2个星期就有一种语言消失,据统计,世界80%的人讲83种主要语言,剩下6000多种语言绝大多数从没有留下语料资料,极为脆弱。一些经济发达的国家是否能给出支持,帮助保护这些濒危语言及其所代表的的民族文化呢?正如Notre Dame巴黎圣母院仅存的一份激光扫描数据那样,当灾难降临后,我们依旧有复制的可能。有些语言,希望在其依稀尚存之际,我们能抓紧时间为它留下一些存在过的印记。
问题:
针对低资源语言的机器翻译,我们应该首先解决低资源的问题,还是机器翻译机器学习的技术问题?
术语:
GAN Generative Adversarial Network 生成对抗网络
POS part of speech 词类
Hangul 韩文,谚文,韩字
Jamo 韩语字母
Logograph 语标文字
作者:
万宇
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向) 查看全部
概要:
由于亚洲国家的语言都缺乏大规模、高质量、广覆盖率的平行语料库,对于语言服务提供者而言,去拓展这样一个市场会产生重大经济、文化和技术的效应,因此,近年发展迅速的神经机器翻译面临不少挑战和机遇,Slator编辑Gino Diño就面向亚洲语言的神经机器翻译发展的相关问题采访了两位专家,分别是在2018亚洲语言自然语言处理国际会议发布论文的刘伍颍研究员和Naver公司的机器翻译研究科学家露西·帕克(Lucy Park)。
亚洲语言的神经机器翻译发展面临的挑战:缺乏可用的语料。
刘伍颖博士称,低资源语言的机器翻译训练数据来源:高校语言专业的教师和学生,建立可比语料库,迁移学习同族语言,以及运用近期热门的生成对抗网络GAN(Generative Adversarial Network)和无监督学习。
亚洲语言的自然语言处理以及神经机器翻译发展态势:未来可期,相较于西方国家语言的发展而言,亚洲语言研究尚处于资源积累的阶段。露西认为,主要基于英德、英法语言对之上的研究,对亚洲语言的研究的有效性有待考证。
如何激发面向亚洲语言的神经机器翻译研究活力:露西认为首先要发展语言专业知识;其次是有公开可用、无版权限制的研究数据;最后,需要更多自然语言处理的开源项目。
面向亚洲语言的NLP和NMT发展中最有潜力的领域:刘伍颖博士认为贸易、电子商务以及技术方面的翻译将获得重点关注。露西•帕克则认为非拉丁文字的自然语言处理以及克服文化语言困难将成为发展潜力巨大的领域。
最后,两位专家还提到目前该领域研究发展较好的学术机构和国内外公司,以及值得关注的技术。
思考:
(1)亚洲语言的语料不足,体现了此前这些国家翻译文化事业发展落后,不少是由于这些国家经济、文化实力不强等历史原因造成的。翻译事业的发展,意味着国家的开放、技术的引进、思想的碰撞、社会的进步。随着 “一带一路”丝绸之路经济带的深入发展,小语种国家将成为经贸、文化、技术开发的新市场,语言服务需求随之也将呈现指数增长。因此,面向这些小语种国家语言的机器翻译发展前景巨大,但想要克服语料资源不足的限制,需要相关学科加大科研力度,仍有很长的路要走。
(2)全世界有7000多种语言,平均每2个星期就有一种语言消失,据统计,世界80%的人讲83种主要语言,剩下6000多种语言绝大多数从没有留下语料资料,极为脆弱。一些经济发达的国家是否能给出支持,帮助保护这些濒危语言及其所代表的的民族文化呢?正如Notre Dame巴黎圣母院仅存的一份激光扫描数据那样,当灾难降临后,我们依旧有复制的可能。有些语言,希望在其依稀尚存之际,我们能抓紧时间为它留下一些存在过的印记。
问题:
针对低资源语言的机器翻译,我们应该首先解决低资源的问题,还是机器翻译机器学习的技术问题?
术语:
GAN Generative Adversarial Network 生成对抗网络
POS part of speech 词类
Hangul 韩文,谚文,韩字
Jamo 韩语字母
Logograph 语标文字
作者:
万宇
北京语言大学高级翻译学院
2019级翻译专业硕士(本地化管理方向)